

.png?width=738&height=411&name=Screenshot%202025-01-20%20at%2008.57.08-min%20(1).png)
Fig 1: Comparing latency and accuracy between the original models from TI with Embedl’s optimized version
Unlocking Edge AI Performance with Embedl's Solutions
Embedl’s innovative solutions for edge AI development offer powerful tools to identify and resolve hardware latency bottlenecks during the deployment of models on edge devices. In this case, Embedl seamlessly integrates with TI’s runtime environment, using it to profile models and their operations directly on the chip. Through advanced model optimization techniques, Embedl can optimize the architecture of even pre-optimized models, eliminating performance bottlenecks and delivering substantial improvements while running models on the edge.
Challenges in Edge AI Deployment
MobileNetV3 represents the latest evolution in mobile-friendly vision models developed by Google. Since the introduction of MobileNet in 2017, which utilized depthwise separable convolutions to reduce computational complexity, the landscape of edge AI has dramatically advanced. However, deploying these models across different hardware, runtimes, and execution environments remains challenging due to the lack of a one-size-fits-all solution.
The design of MobileNetV3 shifted from manual architecture engineering to automated, hardware-aware neural architecture search. Embedl’s suite of algorithms enables similar technology, facilitating hardware-specific optimizations that ensure the best possible model performance on any given hardware. For instance, MobileNetV3’s hard-swish activations and squeeze-and-excite blocks can create issues for quantization and edge deployment, but Embedl’s profiling tools can easily pinpoint these bottlenecks and highlight them in its viewer. This allows for quick adjustments to the model without the need for a complete redesign. A few lines of code using Embedl’s tools allow making modifications to the model instead of having to redesign it from scratch.
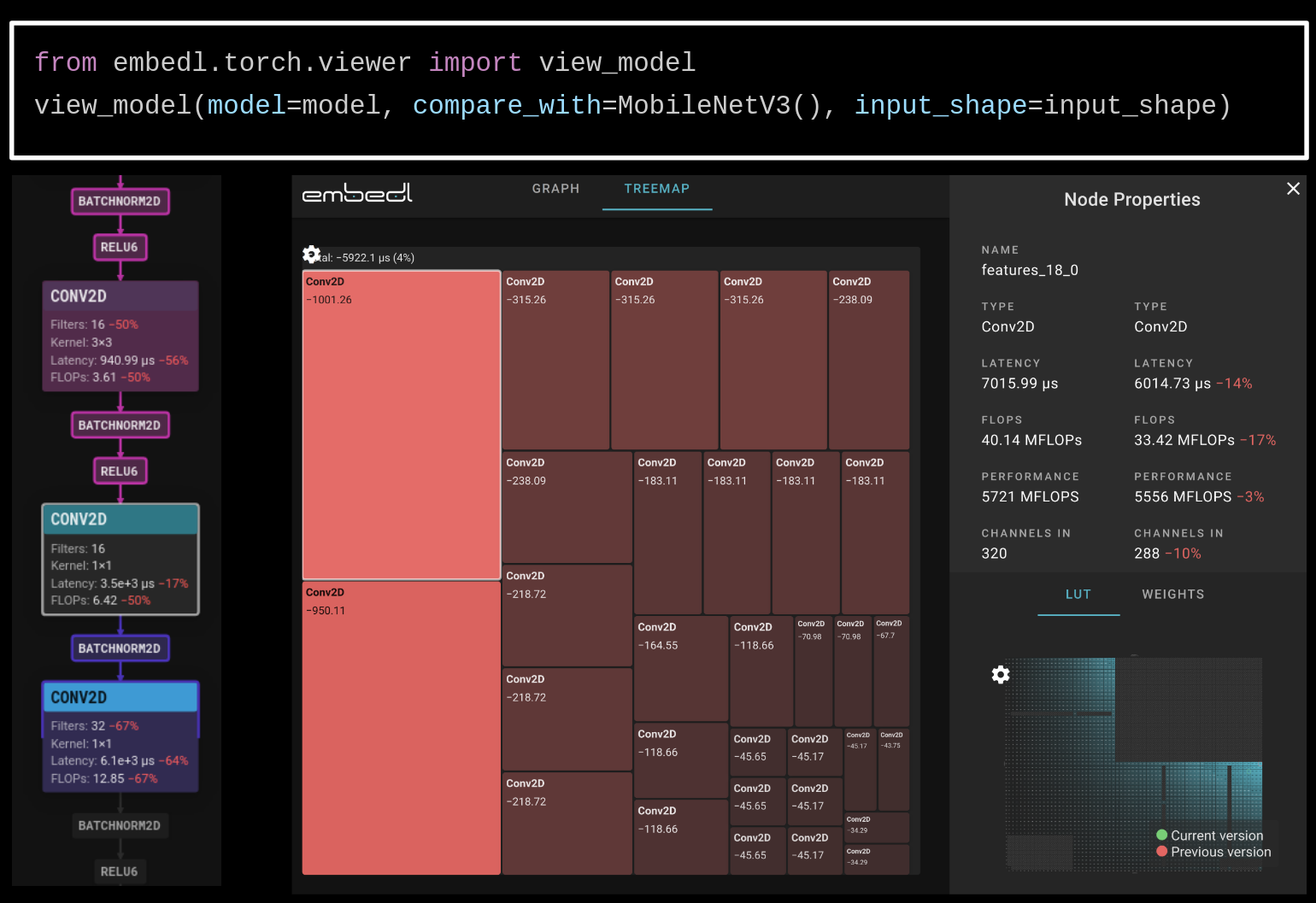
Fig 2: Illustration of how Embedl’s tools simplify profiling model performance, analyzing model changes, and informing design decisions.
Efficient Model Optimization On-the-Fly
In TI’s optimized MobileNetV3 models, elements like hard-swish activations were already converted to ReLUs, and squeeze-and-excite blocks were manually redefined, resulting in the MobileNetV3LiteLarge variant. Embedl’s tools offer the flexibility to make similar adjustments and more to pre-existing models, including standard PyTorch models from the official Torchvision repository without having to re-write the model definition.
The ability to modify model architectures dynamically unlocks new possibilities for exploring optimal configurations tailored to specific hardware targets. Embedl employed this unique technology to enhance TI’s custom MobileNetV3LiteLarge model, achieving a remarkable 18x increase in model execution speed through its advanced hardware-aware optimization techniques.
Hardware-agnostic model optimization
Recognizing that model optimization is not a one-time task, Embedl’s development tools are designed to be modular and compatible with any hardware or software ecosystem for edge AI. This adaptability allows users to build efficient pipelines for model export, compilation, profiling, and inference, simplifying the process of architectural exploration and hardware-specific adjustments.
At the core of Embedl’s approach is a focus on maximizing performance through automated architecture search, model compression, and optimization techniques like advanced quantization and structured pruning. This comprehensive strategy ensures that deep learning models deployed on the edge achieve peak efficiency and performance.