


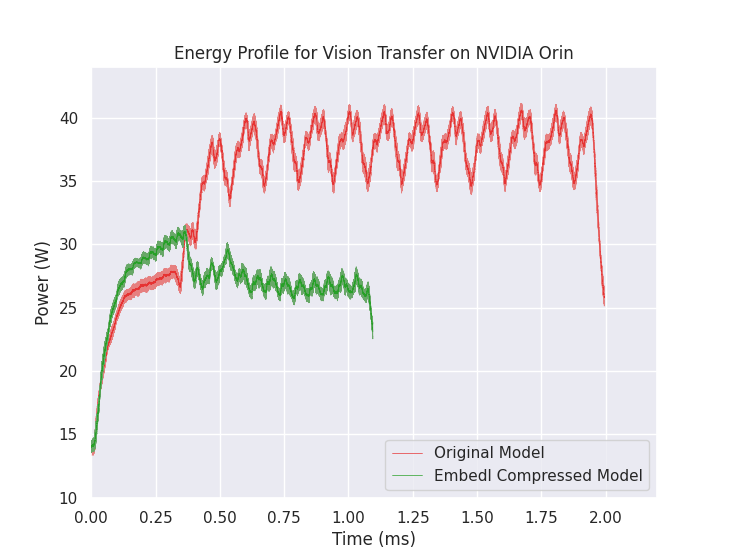
Energy profile of a single inference for models with and without optimization using Embedl’s Model Optimization SDK. The compressed model not only has a much lower latency, but also peak power consumption and average power use are reduced substantially. Shaded represents the range of power consumption over a series of measurements.
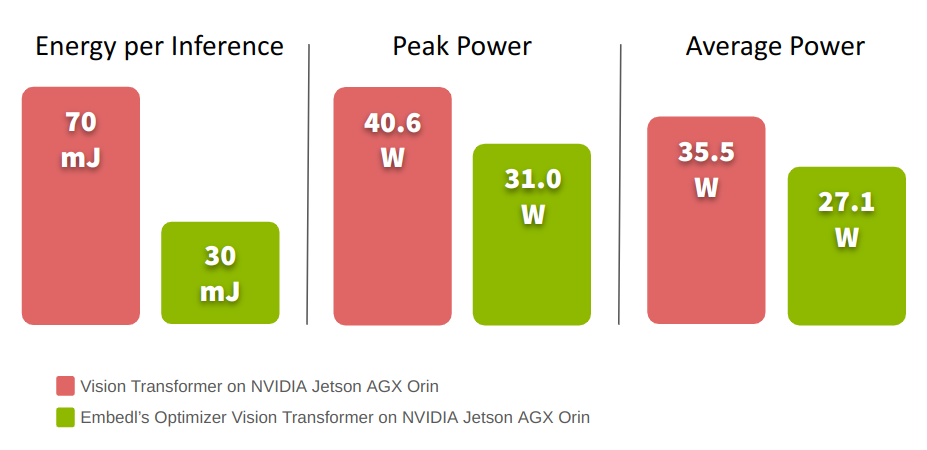
The energy savings that Embedl offers can be illustrated using a machine vision model NVIDIA’s Jetson AGX Orin. Deploying a Vision Transformer model on the Orin requires approximately 70 mJ of energy per inference, with an average power rate of 35.5 W and a peak power requirement of 40.6 W. Compressing the Vision Transformer using Embedl’s Model Optimization SDK reduced the latency by 45% while also reducing the peak power consumption by 23.8% and the average power consumption by 23.6%. The energy per inference was decreased to 30 mJ with a drop in accuracy of less than 1%.
Are you deploying a deep learning model within a tight energy budget? Embedl’s Model Optimization SDK is a versatile tool that combines quantization, structured and unstructured pruning, and NAS to streamline a model’s architecture in order to achieve the best possible performance on your hardware. The flexibility of the tools allows optimization according to any quantifiable metric, including total energy consumption or peak power. Embedl’s tools make it easy to profile a deep learning model’s execution in detail, isolating the impact of individual layers so that maximum performance benefits can be gained with a minimum impact on accuracy.