


Challenges of Running Vision Transformers on Edge Devices
While Vision Transformers have shown strong performance in tasks like image classification and object detection, they are computationally intensive. These models are typically much larger than convolutional neural networks (CNNs), and their self-attention mechanism, which analyzes the relationships between every pair of pixels in an image, demands significant resources.
Deploying Vision Transformers on edge devices like the Nvidia Jetson AGX Orin presents several challenges:
-
High computational demand: ViT models require substantial GPU memory and compute power, often leading to slower inference times.
-
Memory limitations: Edge devices have limited memory resources compared to cloud environments.
-
Power efficiency: Running large models at high throughput on edge devices can consume more power, reducing battery life in mobile systems or increasing operational costs in edge computing setups
Step 1: Efficient Deployment with TensorRT
The Embedl SDK makes use of TensorRT to efficiently compile, profile, and evaluate models on the Jetson AGX Orin. TensorRT is a deep learning inference engine that delivers low-latency, high-throughput inference on Nvidia GPUs.
TensorRT provides multiple optimization techniques, such as:
-
Kernel fusion: Combining operations like convolutions and activations to minimize memory overhead.
-
Dynamic tensor memory allocation: Allocating memory only when needed during runtime to reduce memory consumption.
Optimal compiler settings and environment for inference allowed us to achieve a latency of 3.6 ms for the Vision Transformer model.
Step 2: Integer Quantization
Quantization involves reducing the precision of the model weights and activations, which can drastically decrease the computational and memory requirements. While quantization can be used to represent model weights with any precision, the inference engine is typically optimized only for specific precision levels. TensorRT supports multiple different precision levels, depending on what operator types are used in the model.
However, there is a common pitfall when applying low-bit quantization. In the TensorRT compilation process, it will by default decide what quantization strategy makes the model execute the fastest, which is not always the best from an accuracy view point. With Embedl's SDK we were able to apply advanced quantization techniques to make sure the model's accuracy is not negatively impacted by applying quantization.
Results of Quantization:
-
Precision: Low-bit integer quantization with critical structures maintained at floating point precision.
-
Inference speedup: 2x speedup
-
Accuracy drop: Insignificant (less than 0.01%)
Step 3: Structured Pruning
To push performance even further, and unlock the full potential of transformer inference on the Nvidia Orin, we applied structured pruning to the model. Similar to quantization, different hardware platforms will require intricate choices of structures to prune to reach optimal results. With the Embedl SDK, these structures could be identified and automatically pruned, reaching an optimal model for the Nvidia Jetson AGX Orin.
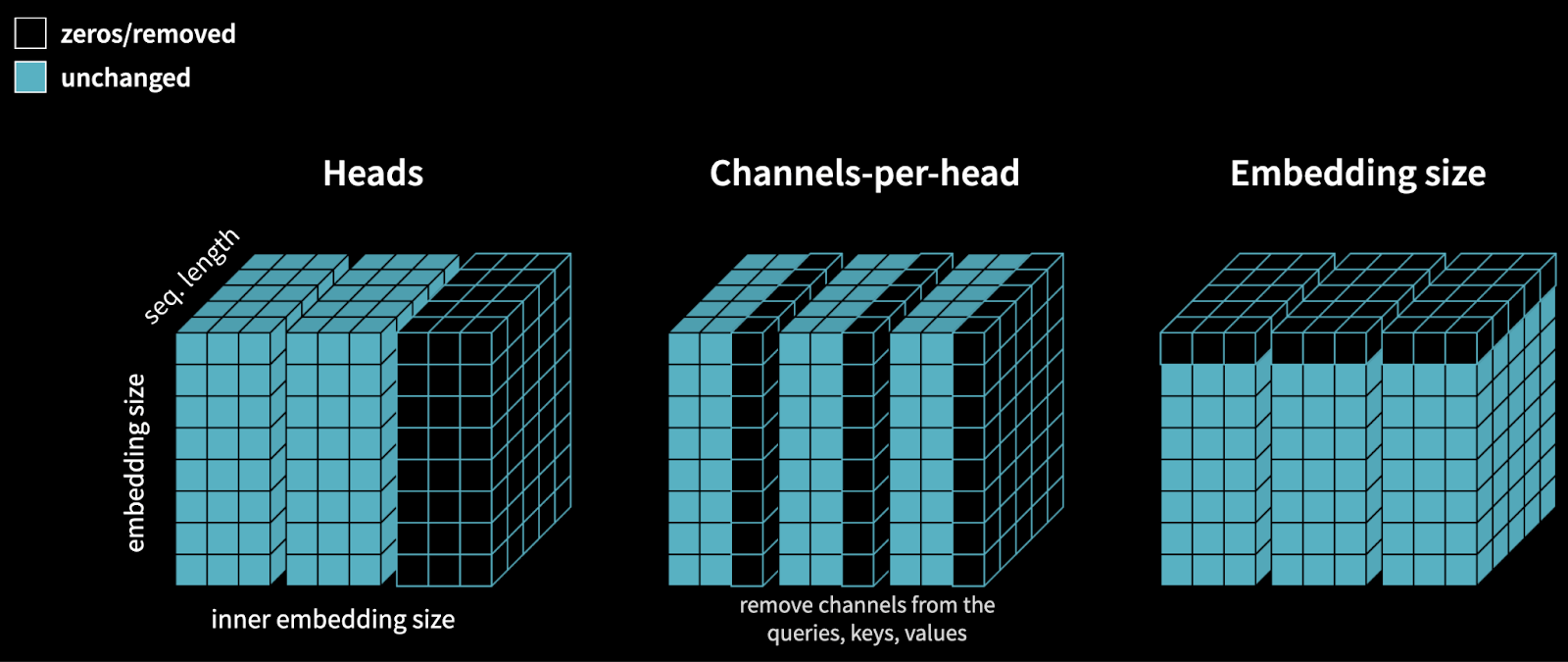
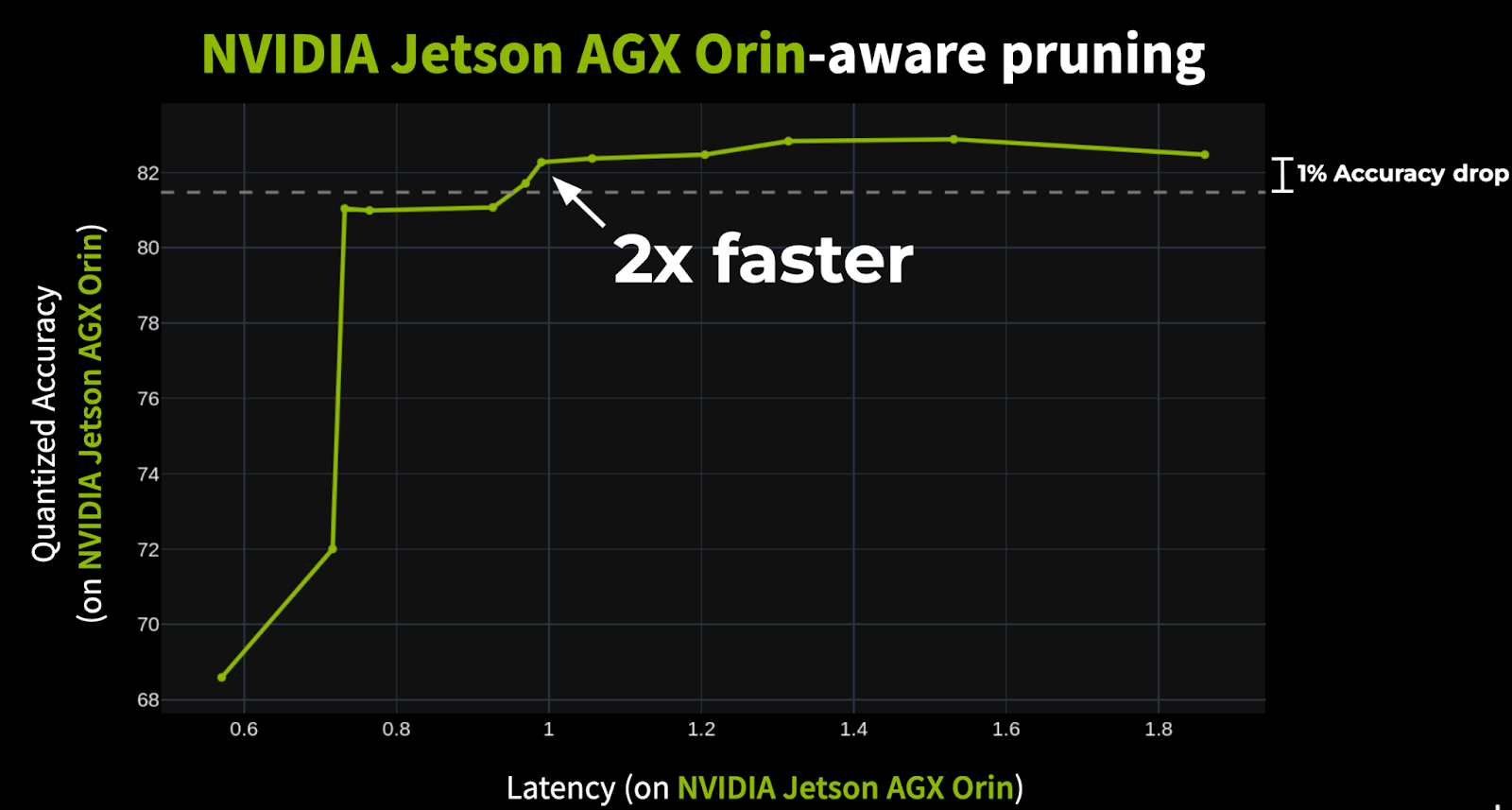
Results of Structured Pruning:
-
Energy per inference reduction: 2.3x
-
Inference speedup: 2x
-
Accuracy drop: Less than 0.1%
Conclusion
By leveraging Embedl's Model Optimization SDK, we successfully optimized the Vision Transformer model for deployment on Nvidia's Jetson AGX Orin, overcoming the significant challenges posed by its computationally demanding architecture. Through a combination of TensorRT-based deployment, low-bit integer quantization, and structured pruning, we achieved a remarkable 4x improvement in inference speed and over 2x reduction in energy consumption, all with less than a 1% decrease in accuracy. These results demonstrate the potential of optimizing state-of-the-art transformer models for edge devices, enabling real-time applications while maintaining power efficiency and performance. This case study highlights the importance of using tailored optimization strategies to unlock the full potential of deep learning models on resource-constrained hardware.
Interested in optimizing your models for edge devices? Learn more about Embedl's solutions.