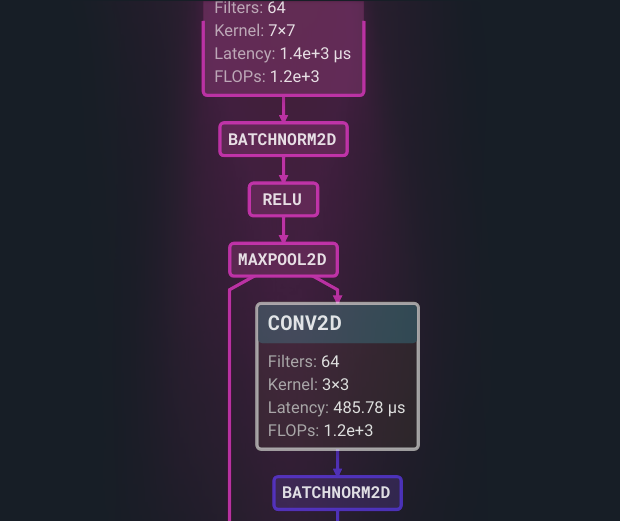
.png "Embedl Model Optimization SDK (23)")
Supporting multiple hardware platforms
Deploy Anywhere – The Embedl SDK supports a wide range of hardware platforms, making it easy to optimize and run your AI models across CPUs, GPUs, embedded processors, and edge AI accelerators, without rebuilding your pipeline for each device.
Easy to Integrate
Designed to work with your team’s existing tools and workflows. Smooth onboarding with access to guides, workshops, and tutorials.
Stay Ahead of Competitors
Faster, more efficient AI gives your product a market edge. Impress customers with innovation they can feel, speed, responsiveness, and more innovative features. Use lightweight models that require less memory, power, and storage. Ideal for edge devices, such as wearables, drones, or IoT products.
Cut Costs
At the bottom line, our customers get more out of their AI teams and can reduce the cost of their BOM.
Reduce Risk
Embedl SDK produces consistent, repeatable results, no more trial-and-error. Backed by expert support, documentation, and training.
Save Time
Accelerate AI deployment by replacing months of manual tuning with just hours of automated optimization. Get your product to market faster with fewer delays.