

In this case study, we will focus on the Lightweight Atrous Spatial Pyramid Pooling (LRASPP) model, an architecture specifically designed for efficient semantic segmentation on mobile and embedded platforms. We will examine how this model can be adapted and optimized for real-time performance on TI’s TDA4VM. Texas Instrument has a great toolchain (TIDL) that allows users to compile e.g. ONNX models to executable code on the device.
Model Compatibility with TIDL
LRASPP for semantic segmentation was first introduced in [2] and employs a MobileNetV3 backbone paired with a Light-RASPP head. At the time of writing, the MobileNetV3 architecture was not natively supported in TIDL, mainly due to its squeeze-and-excitation blocks and hard-swish activations. To address this, we adapted the LRASPP model by replacing the MobileNetV3 backbone and modifying the head using Embedl’s Model Optimization SDK, see Figure 1.
While adapting the LRASPP model for compatibility with TIDL addresses the architectural limitations, running real-time semantic segmentation on resource-constrained hardware like the TDA4VM still poses significant challenges in terms of processing power, memory bandwidth, and energy consumption. We optimized the model further to ensure it meets both latency and accuracy requirements in real-world applications.
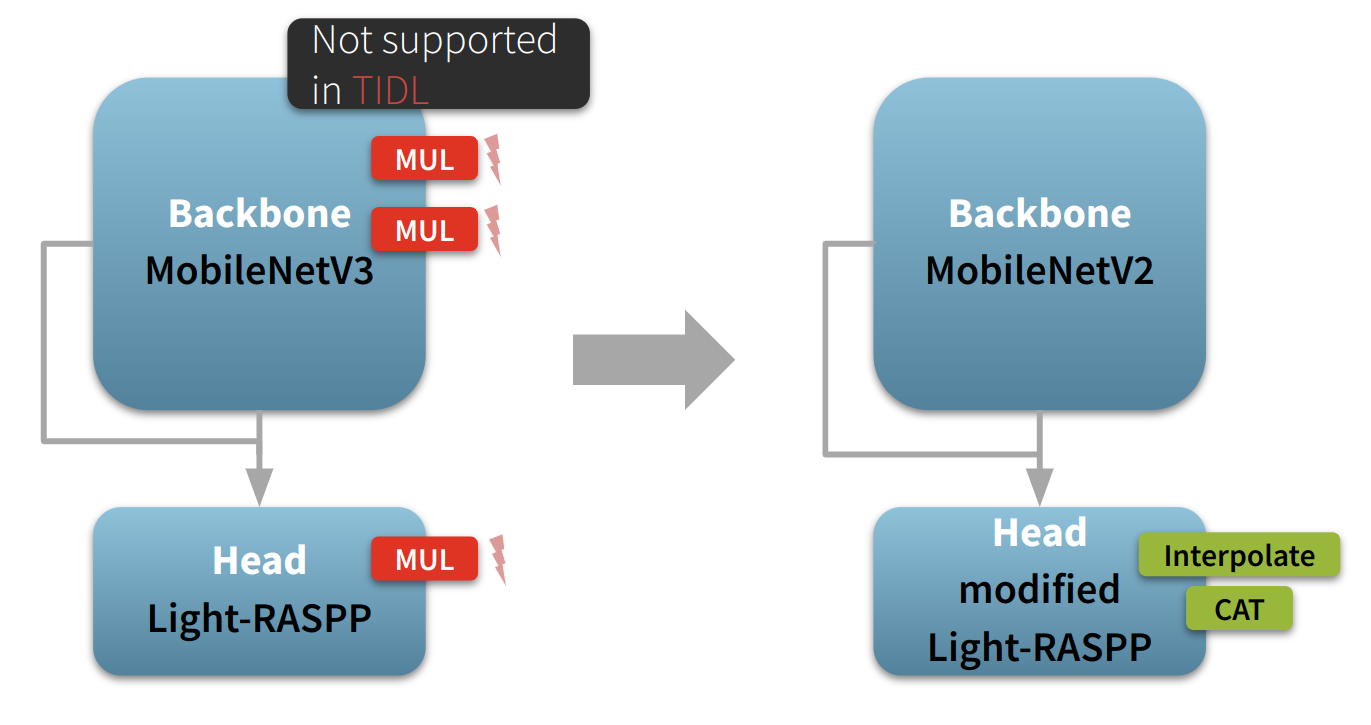
Figure 1: Adaptation of the LRASPP model for TIDL compatibility. The original LRASPP architecture (left) with a MobileNetV3 backbone is not fully supported by TIDL due to operations like multiplication (MUL). To address this, the backbone is replaced with MobileNetV2, and the head is modified to use operations like interpolation and concatenation (CAT).
Hardware-Aware Model Compression for TI’s TDA4VM
This is where Embedl’s latency-aware model compression techniques come into play. By taking into account the specific characteristics and limitations of the target hardware, these methods are designed to reduce the model’s size and computational load with near-original accuracy. One such technique is latency-aware pruning. Embedl’s tools are not limited to pruning, but for brevity, we only demonstrate pruning in this use case. The pruned LRASPP model was benchmarked on the TDA4VM platform, and the results are shown in Table 1.
|
Network* |
mIoU |
Latency |
Speedup |
|
Baseline (INT8) |
53.3 |
46.76 |
1x |
|
Pruned (INT8) |
52.4 |
15.5 |
3x |
Table 1: Hardware-aware compression results of LRASPP for TI’s TDA4VM including quantization. All latencies are in ms. mIoU on Microsoft COCO [3]. *modified LRASPP as depicted in Figure 1.
Conclusion
In this case study, we demonstrated the successful adaptation and optimization of the LRASPP semantic segmentation model for deployment on Texas Instruments' TDA4VM, a platform designed for autonomous driving applications. By addressing the initial compatibility limitations of the MobileNetV3 backbone with TIDL, we modified the model using a MobileNetV2 backbone and a redesigned Light-RASPP head.
To further optimize the model for the resource-constrained environment, we applied Embedl’s latency-aware model compression techniques, in this case, pruning. The pruned model achieved a notable reduction in latency—15.5 ms compared to the 46.76 ms of the baseline, which is a 3x speedup—while maintaining competitive accuracy with only a minimal drop in mIoU on Microsoft COCO (52.4% vs. 53.3%).
[1] TDA4VM (no date) TDA4VM data sheet, product information and support | TI.com. Available at: https://www.ti.com/product/TDA4VM#description (Accessed: 12 September 2024).
[2] Howard, Andrew et al., 2019. Searching for mobilenetv3. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 1314-1324).
[3] Tsung-Yi Lin et al., 2014. Microsoft COCO: Common Objects in Context. CoRR, abs/1405.0312. Available at: http://arxiv.org/abs/1405.0312.